
10 notwendige Fähigkeiten für eine effiziente, intelligente Datennutzung


Autor:innen: Timm Grosser, Nina Lorenz
“Du brauchst eine Datenstrategie“ ist die generische Antwort auf die Datenprobleme der Unternehmen. Doch was ist der Umfang einer effektiven Strategie und warum ist es schwierig, aus Daten einen Mehrwert zu schaffen? Welche betriebswirtschaftlichen, technischen und organisatorischen Herausforderungen gilt es zu bewältigen? Dieser Beitrag ist der zweite Teil einer drei-teiligen Blog-Reihe und liefert Einblicke zur effizienten Datennutzung in Zeiten komplexer Datenlandschaften und mannigfaltiger, unternehmensweiter Anwendungsfälle.
Daten allein schaffen keinen Nutzen, denn sie bilden keine Entscheidungsgrundlage. Gemeinhin hört man in diesem Kontext oft, Daten seien das neue Öl. Diese Aussage impliziert nicht nur die Relevanz von Daten für Unternehmenserfolg. Vielmehr steckt in der Aussage auch, dass - genau wie Rohöl - Daten erst nach ihrer Verarbeitung wertvoll werden.
Wann werden Daten nutzbar?
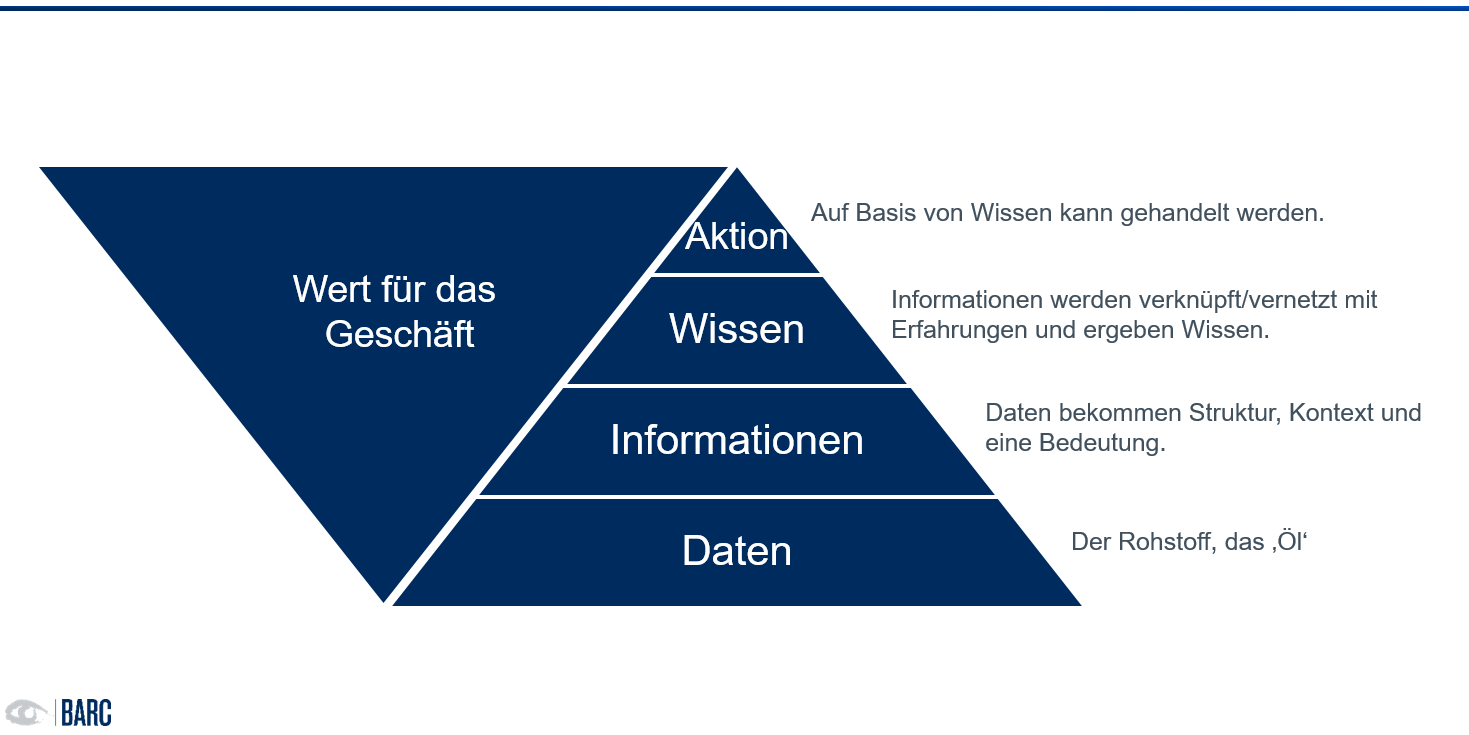
Daten durchlaufen einen mehrstufigen Veredlungsprozess, bevor sie zu einer sinnvollen, zielführenden Aktion führen können. Werden Daten in Kontext mit zughörigen Daten gestellt, entstehen Informationen. Diese sind verständlich, relevant, zeitnah.
Nutzen aus Daten zu schöpfen, bedarf Wissen.
Informationen sind bereits für echte Entscheidungen hilfreich. Sie reichen jedoch bei weitem nicht für die Bearbeitung komplexer Sachverhalte, wie sie die heutige Unternehmensrealität prägen. Denn reine Informationen beinhalten keine verlässliche Bewertung und Einordnung. Fundierte Entscheidungen brauchen Wissen. Im Kontext von wertschöpfendem Wissen und im Bezug auf Daten sprich man oft von Business Knowledge. Diese umfasst Fähigkeiten, Erfahrungen, Fertigkeiten und Expertenwissen, die in den Unternehmen geschaffen werden. Als gemeinsame Ressource prägt und beeinflusst Wissen alle Aktivitäten in und um ein Unternehmen. Echten Nutzen stiften Daten also nur in Kontext und zusammen mit der richtigen Business Knowledge (Abb. 1).
Das Beispiel eines Telco-Unternehmens soll dies verdeutlichen:
Das Telco-Unternehmens erfasst und speichert über Jahre die Call Detail Records (CDR) ihrer Kunden für die Abrechnung. Der einzelne CDR-Datensatz (das Öl) beinhaltet Daten über Nummern der Gesprächsteilnehmer, Uhrzeit und Dauer der Verbindung, das Endgerät, Funkzelle usw. Geschäftsrelevante Aussagen zum Kunden oder Umsatz können damit nicht getroffen werden. Erst recht können mit diesen Rohdaten keine Entscheidungen zur Optimierung des eigenen Geschäfts oder eine erweiterte Wertschöpfung gemacht werden. Auch wenn die Datensätze mit den Stammdaten des Kunden und des gewählten Tarifs verknüpft werden, können noch keine geschäftsrelevanten Aussagen – zum Beispiel zur Profitabilität eines Tarifs - gemacht werden. Erst wenn weitere Dimensionen und Aspekte wie Tariftypen, Kundentypen, Geocluster etc. mit den Daten in Kontext gesetzt werden, entstehen Informationen, die zumindest eine sinnvolle Auswertung des Nutzungsverhaltens erlauben. Wenn das Unternehmen jedoch herausfinden möchte, welche Kunden wahrscheinlich abwandern oder weitere Services kaufen würden, muss es sich auf das Wissen der Mitarbeitenden verlassen. Sie:
- wissen, welche Maßnahmen unter Einbeziehung ihrer Erfahrung erfolgsversprechend sind,
- sind in der Lage aus Kundengespräche entsprechende Rückschlüsse zu ziehen
- können bewerten, ob Kunden bereits länger unzufrieden sind oder Beschwerden vorliegen
- können einschätzen, wie gravierend diese Beschwerden sind.
Erst wenn dieses Wissen bei der Auswertung berücksichtigt wird, können auch Entscheidungen (Aktionen) zu Tarifen, Upselling-Möglichkeiten etc. getroffen werden.
Erfahrungswerte: Warum ist Wissen nicht selbstverständlich?
Daten sinnvoll zu nutzen geht also über das reine Sammeln und Aufbereiten hinaus. Aus BARC Studien wissen wir, dass Unternehmen hier besondere Schwierigkeiten haben.
Unsere weltweit durchgeführte Studie Data Black Holes – Are Data Silos Undermining Your Digital Transformation (Juni 2021) mit eindeutiger Botschaft: Unternehmen, die Daten mit Wissen und Bedeutung verbinden, nutzen Daten erfolgreicher. Es liegt am einheitlichen Verständnis von Daten, an der Interpretierbarkeit, am verfügbaren Wissen zu Kontext und Verwendung.
Wissen mit Daten zu verknüpfen ist allerdings alles andere als trivial. Datenlandschaften sind heterogen und komplex, die organisatorischen Hürden oftmals hoch. Nicht selten fehlen im Unternehmen Strukturen, Know-How oder auch einfach das Commitment des Managements, in die passende und notwendige Infrastruktur und Ressourcen zu investieren (Abb. 2). Auch fehlt in der Regel Transparenz über die Wirkung guter und schlechter Daten auf gefällte Entscheidungen. Die genannten Aspekte bilden seit Jahren die Top-Herausforderungen im Datenmanagement. Das bestätigt eine Reihe an Studien Leverage your Data (2020), How to Rule Your Data World (2018). Neu ist allerdings, dass diese Herausforderungen als elementarer für den Unternehmenserfolg wahrgenommen werden. Das ist auch deutlich spürbar in der steigenden Anzahl von Projekten zur Konkretisierung von Datenstrategien.
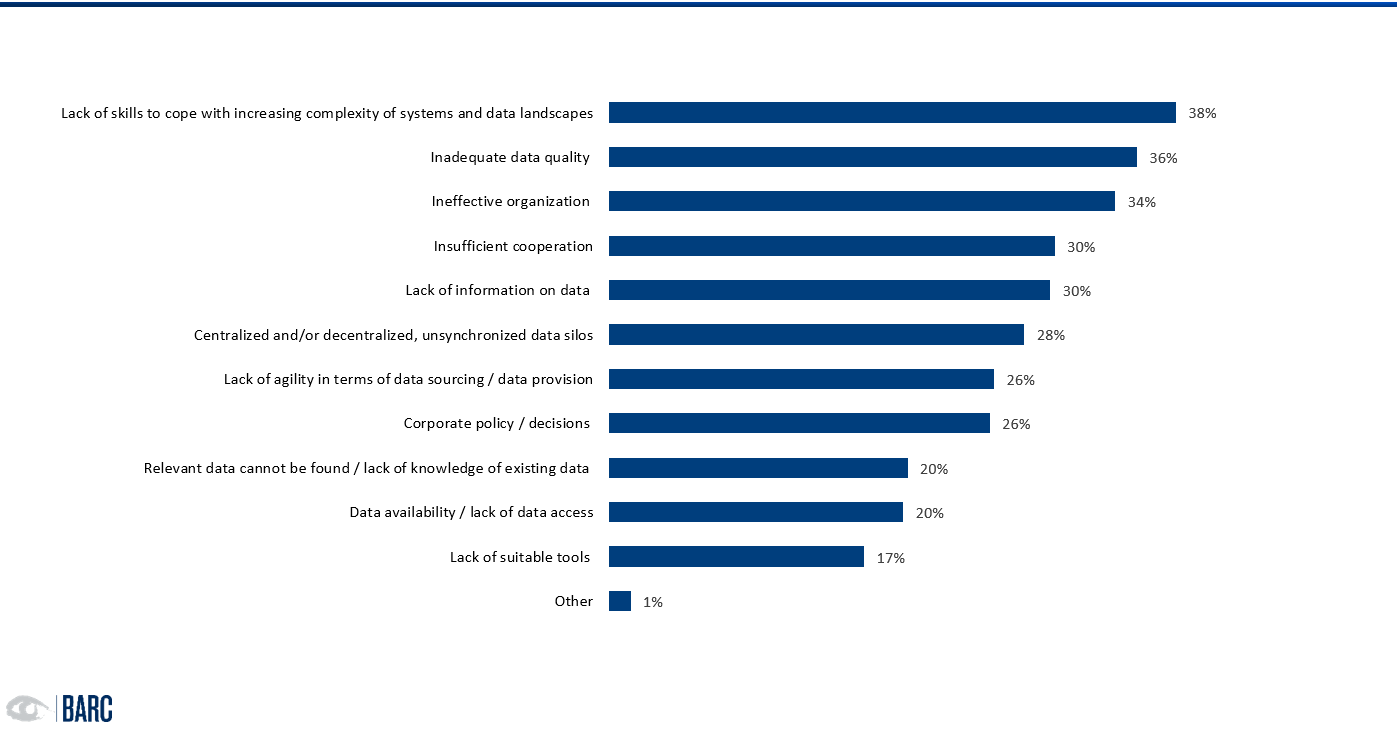
Dennoch, die Liste der Probleme, mit denen sich Unternehmen bei der Arbeit mit Daten auseinandersetzen, ist lang.
Selbst diejenigen, die die Fähigkeiten und Kompetenzen im Umgang mit Daten in ihrem Unternehmen als deutlich besser einschätzen, haben in verschiedenen datenbezogenen Bereichen noch zu kämpfen. Als Gründe werden am häufigsten genannt (Abb. 3):
- fehlendes Expertenwissen und Datenverständnis
- Schwierigkeiten bei der Datenaufbereitung und -integration, u.a. verursacht durch schlechte Datenqualität und mangelnde Datenverfügbarkeit
- fehlende Nutzbarkeit der analysierten Daten in Business-Prozessen, häufig aufgrund fehlenden Datenverständnisses und Expertenwissen
Das hat Implikationen für die Stabilität und Effizienz der bestehenden daten-basierten Prozesse und die Innovationskraft des Unternehmens.
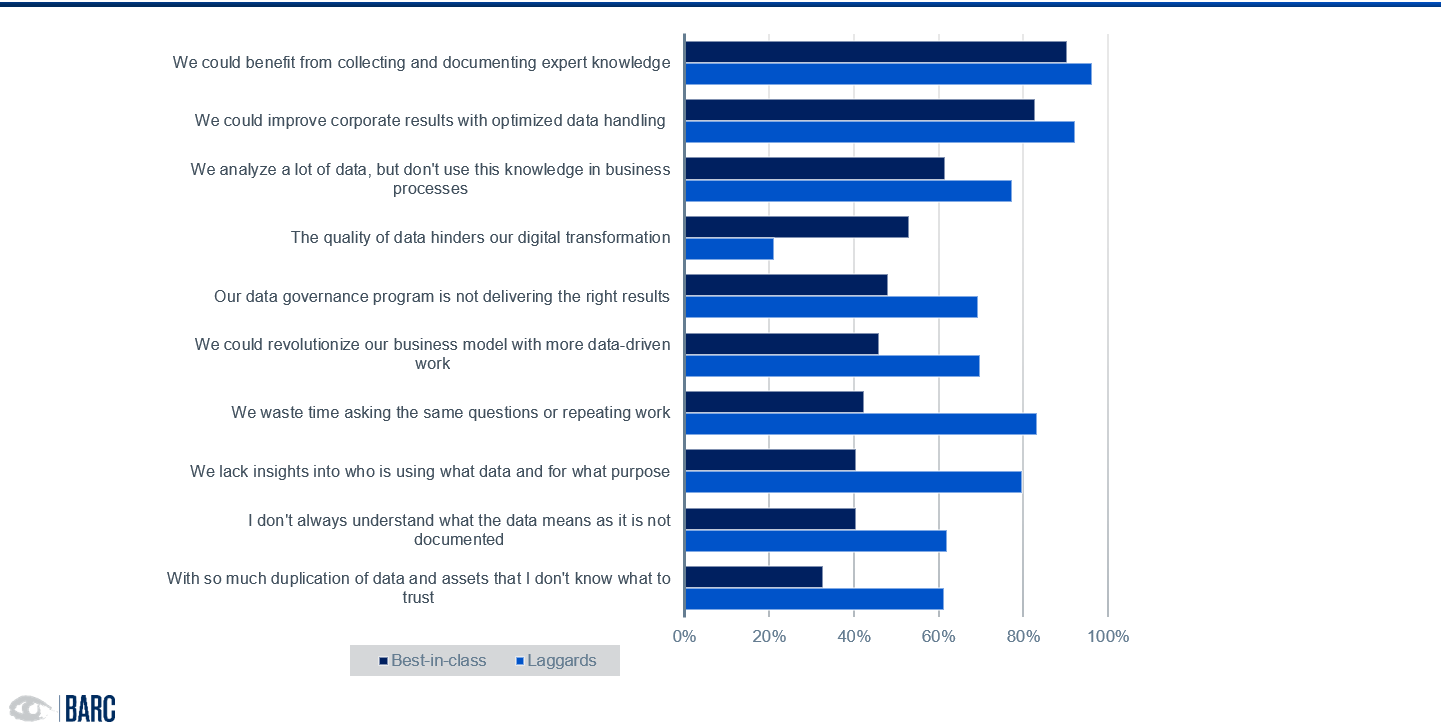
Nun zur guten Nachricht
Es gibt Lösungsansätze. Im letzten Blogbeitrag haben wir diese bereits vorstellt. Nun möchten wir konkreter werden und aufzeigen, welche relevanten Funktionen eine Lösung mitbringen muss, damit Daten gefunden, verstanden und genutzt werden können.
Wie gelingt die Verknüpfung von Daten und Wissen mithilfe von Technologie?
Ohne eine Datenkultur, welche die Verknüpfung von Daten, Bedeutung (Semantik) und Wissen als oberstes Gut sieht, nutzt jedoch die beste Datenmanagementlösung nichts. Eine daran ausgerichtete Datenstrategie und die Förderung des entsprechenden Know-hows im Unternehmen kommen hinzu. Dies möchten wir als These vorwegschicken. Daten zu beschreiben und per Metadaten mit Wissen (zu den Daten, zu Methoden, zur Verwendung etc.) zu verknüpfen bedarf einer Toolunterstützung.
Tools können helfen, Komplexität zu kapseln, einen Zugang zu Daten zu schaffen und die Akzeptanz für die Arbeit mit und Pflege von Daten entscheidend zu erhöhen. Unserer Ansicht bedarf die nachhaltig effiziente Datennutzung eines Tools, das hilft, Daten und Wissen sowohl zu verknüpfen und zu verwalten, als auch auffindbar und nutzbar zu machen.
Ein Tool sollte daher die folgenden Top 10 fachlichen Anforderungen adressieren:
- Auffindbarkeit und Datenverständnis
Daten müssen über die Systeme hinaus, in denen sie gespeichert und genutzt werden, eindeutig identifiziert werden können. Zudem müssen sie per Metadaten mit einer verständlichen Beschreibung verknüpft sein, damit jede Person genau und korrekt versteht, was diese Daten bedeuten. Der Schlüssel hierfür sind Terminologien und Ontologien, die ein gemeinsames, teilbares Verständnis zu Daten schaffen. Die Definition und die effiziente Kontrolle zur Einhaltung von Standards ist dafür unerlässlich. Wie relevant ein gemeinsames Datenverständnis ist und welchen Wert es für das Unternehmen hat, zeigt die bereits oben referenzierte BARC Studie: „Data Black Holes - are data silos undermining digital transformation?“ - Vertrauen in Daten durch Transparenz
Datennutzer*innen müssen den Daten selbst und den Beschreibungen vertrauen können. Es bedarf deshalb einer leicht nachvollziehbaren und zugänglichen Dokumentation der Herkunft, Entstehung, Beschaffenheit, Verwendung und Zuständigkeiten der Daten. Dies erfolgt ebenfalls über die Metadaten. Die wohl bekanntesten funktionalen Anforderungen hier sind Data Profiling (Datenqualitätsanalyse) sowie Data Lineage/Provenance/Impact-Analysen wie auch die Bewertung durch andere Nutzer*innen (Rating). - Nahtlose Integration in die bestehenden Systeme und Prozesse
Die möglichst nahtlose Integration in das bestehende Ökosystem und in den bekannten Arbeitsplatz fördert Akzeptanz und Effizienz in der Nutzung. Integration ist der Schlüssel in zunehmend heterogenen Systemlandschaften bei gleichzeitigem Wunsch eines möglichst einheitlichen Zugriffs auf Daten. „Noch ein neues Tool" stößt häufig auf Abneigung bei den Nutzern. Der Schlüssel liegt u.a. in der Integrierbarkeit in das bestehende System- und Prozesslandschaft-Ecosystem und in der Einfachheit der Anwendung (Punkt 10). - Konnektivität zu Datenquellen
Bestehende Systeme müssen möglichst einfach und schnell angebunden werden können, um Metadaten und Daten auslesen zu können. Die Schnittstellen sollen darüber hinaus robust gegenüber Änderungen sein. Besonders hilfreich sind Konnektoren die dabei unterstützen, hochkomplexe Quellen anzubinden (z. B. Anwendungen mit gekapselten Daten wie SAP). Crawler helfen zusätzlich dabei, Informationen aus unstrukturierten Daten zu generieren, bspw. Python, Java-Code. - Erweiterbarkeit und Adaptierbarkeit der Lösung
Kein Unternehmen gleicht dem anderen. Zudem erfordert ein hochdynamischer Markt eine schnelle Anpassbarkeit. Vor dem Hintergrund können starre Strukturen zur Herausforderung werden. Vielmehr fordern Unternehmen eine offene und frei erweiterbare Plattform. Damit gemeint ist vor allem die Erweiterbarkeit des Modells sowie die funktionale Skalierfähigkeit. So muss ein Tool in der Lage sein, einfach und ohne viel Aufwand neue Daten- oder Wissensobjekte und Attribute zu integrieren. Es muss darüber hinaus offen, verknüpfbar und dokumentiert sein. Schließlich sollen die Datenschema bei Änderungen des Geschäftsmodells oder neuen Geschäftsmodellen schnellstmöglich und mit geringem Aufwand angepasst werden können. Die Nutzung von vordefinierten Inhalten ist, unserer Erfahrung nach, dahingegen wenig gefragt. Vielmehr gilt es, ein Modell zu liefern, das hilft, flexibel die unterschiedlichen Perspektiven und Benennung der Stakeholder zusammenzubringen. So nutzen z. B, Controlling, Sales, Marketing, Entwicklung und externe Unternehmen Daten durchaus unterschiedlich und verwenden auch eigene Benennungen. Kunden werden mitunter je nach Abteilung als Customer, Prospect, Lead, Follower, Stammkunde oder Kunde geführt. - Automation
Die Automatisierbarkeit von Prozessen verringert die Last für die Nutzer*innen und fördert die Akzeptanz und den Nutzen der Lösung. Automatisierbarkeit wiederum funktioniert nur mit Vertrauen in die Daten (Punkt 2). Sie stellt zugleich das größte Potential bezüglich Kosten- und Zeitoptimierung dar: vom Aufbau und der Administration des Wissensportales, über die Identifikation, Extraktion, Anreichung und Verknüpfung der Daten bis hin zur eigentlichen Nutzung. Automatisierbare Teilaufgaben reichen vom Auslesen von maschinengenerierten Metadaten bis zur Lösung komplexer Aufgabenstellungen, wie der Verknüpfung von Wissen mit Daten oder der fachlichen Beschreibung von Daten, die aktuell häufig noch manuell erfolgt. Die Anforderung dabei ist, den Aufwand für die Dokumentation der Daten für die Nutzer*innen so gering wie möglich zu halten. - Wissen schaffen und teilen
Daten beschreiben, verknüpfen und Wissen hinzufügen, sind heute oftmals manuelle Tätigkeiten. Es geht dabei um die Umsetzung eines schnellen, einfachen Wissenstransfers. Dafür muss implizites Wissen zu expliziten Wissen transformiert werden. Das heißt, es muss aus den Köpfen der Expert*innen digitalisiert werden - menschenverständlich und maschinenlesbar. Das Werkzeug sollte für diese Aufgabenstellung unterschiedliche Ansätze unterstützen, Wissen zu erfassen: sowohl zentral durch eine*n Hauptverantwortliche*n wie auch dezentral aus der Gesamtheit an Mitarbeitenden (Crowd wisdom). Bei der Motivation der Mitarbeitenden kann ein Tool z. B. mit Gamification Features unterstützen. In jedem Fall sollte es eine intuitive und einfache Möglichkeit bieten (Punkt 10), sich schnell in den Daten zurechtzufinden, diese analysieren zu können (im Sinne Beziehungen, Zusammenhänge) sowie einfache Workflows anzubieten wie bspw. ein Approval Prozess. Es muss in die internen Prozesse integrierbar sein und damit idealerweise gleich dort Wissen erfassen können, wo die Daten entstehen (Punkt 3 und 4). - Daten richtig und übergreifend nutzen dank Kollaboration & Governance
Kommunikation und Kollaboration sind Erfolgsfaktoren und ein wesentlicher Teil, um Wissen zu Daten zu erfassen. So sollten Kommentare zu Daten, Warnungen, Hinweise, Verwendungstipps etc. Teil einer jeden Lösung sein, um Transparenz zur Nutzung und Verwendung von Daten oder Informationsobjekten zu teilen. Unterstützend wirken können Chats, E-Mail Benachrichtigungen, Foren oder Workflows. Klassische Governance-Disziplinen wie Policy Management stellen sicher, dass die Nutzung der Daten, der Metadaten (mit denen das Wissen abgebildet wird) und des Tools einheitlich und sorgfältig erfolgt. - Einhaltung der unternehmensweiten Security & Privacy Richtlinien
Die Fähigkeit zur Einhaltung der Security und Privacy Richtlinien ist essentiell. Dies umfasst mehrere Facetten: Datenzugriff (Zugang und Berechtigung), nahtlose Integration via Single-Sign-On (SSO), Verschlüsselung der Kommunikation (z. B. per SSL), Data Privacy (Masking, Anonymisierung) sowie die Klassifikation von Daten gemäß Sicherheitseinstufung. Eine klare, transparente Regelung und Kontrolle über die Security & Privacy wird von unseren Kunden oft nachgefragt. - Einfache, intuitive Nutzbarkeit für Jedermann
Schlussendlich muss das Tool maximale Usability bieten. Die Antwort auf eine Fragestellung muss in einer individuell verständlichen und klaren Sprache vorliegen, unabhängig davon, ob ein Manager, ein Business User, ein Entwickler oder ein Techniker oder gar eine Maschine die Frage gestellt hat. Dies betrifft sowohl die Recherche in Metadaten als auch den eigentlichen Datenzugriff. Das Werkzeug muss denkbar einfach in der Anwendung sein und den Nutzer*innen helfen, sich in der Datenwelt effizient zurechtzufinden. „Warum ist Google wohl so erfolgreich geworden?“ Richtig, sie haben Wissen mit Daten verknüpft in einer Form verknüpft, die für jede Person verständlich ist.
Was digitale Pioniere gemein haben
Insbesondere wenn es um die Verknüpfung von Daten mit Wissen geht, fällt häufig der Begriff "Datenkatalog". Knowledge Graphen bieten als Tool für Datenkataloge und darüber hinaus einen hoch interessanten Ansatz. Die Technologie ist zwar in historisch durch relationale Technologien geprägten Unternehmen noch immer verhältnismäßig wenig sichtbar. Das hat jedoch vor allem unternehmenskulturelle Gründe. Dadurch wird häufig das Potential für Knowledge Graphen verkannt.
Unserer Ansicht bedarf die nachhaltig effiziente Datennutzung
eines Tools, das hilft, Daten und Wissen sowohl zu verknüpfen und zu verwalten,
als auch auffindbar und nutzbar zu machen.
Ein Indiz für das Potential liefert die Verbreitung der Technologie bei digitalen Pionieren und Datenunternehmen wie Facebook, Amazon, Google, Alibaba, aber auch Banken wie Morgan Stanley und Medienhäusern wie die BBC. Meiner Einschätzung nach haben die meisten Unternehmen das Potential von Knowledge Graphen noch nicht voll erkannt und verstanden. In Zukunft sollte der Einsatz insbesondere von BI und Analytics Expert*innen, aber auch dem Infrastruktur- oder Produktmanagement geprüft werden.
Denn wenn es um die Verknüpfung von Wissen und Daten geht, sind Knowledge Graphen ein passender Ansatz. Sie ermöglichen, Kontext und Beziehungen zwischen Datenobjekten im Unternehmen direkt an den Daten zu beschreiben. Durch die Verknüpfung des Kontexts mit den Realdaten per Metadaten machen die Graphen Daten für Mensch und Maschine gleichermaßen lesbar und interpretierbar. Die Modellogik vermeidet Inkonsistenzen in der Bedeutung von Daten und kann den Analysten vor unnötigen Datenaufbereitungsarbeiten oder unnötigen Kommunikationsschleifen schonen. Auf der anderen Seite steht eine Non-SQL-Expert*innen-Technologie mit speziellen Schnittstellen, die eine Integration in das bestehende Ecosystem oder den Einsatz zusammen mit SQL-orientierten Auswertetools erschweren kann.
Unterm Strich sehen wir viele Potentiale der Knowledge Graphen als eine wertvolle Ergänzung für das Daten- und Wissensmanagement.
Im letzten Teil der Blogreihe erfahren Sie, wie Datenprojekte erfolgreich umgesetzt werden können und welche Relevanz die Datenverfügbarkeit dabei spielt.
——————————————————
Nina Lorenz ist Analystin für Data & Analytics am Business Application Research Center (BARC). Sie ist Co-Autorin von Blogposts, Artikeln und Forschungsstudien im Bereich Data & Analytics. Außerdem ist sie für die Konzeption und Implementierung von Power BI, Azure Analytics und Qlik Content Browser verantwortlich. Derzeit erforscht sie, wie unterschiedliche Organisationsstrukturen die Datenkultur im datengetriebenen Unternehmen beeinflussen und potenziell ermöglichen.
Timm Grosser ist Senior Analyst Data & Analytics im Business Application Research Center (BARC). Seine Expertise umfasst Strategiedefinition, Konzeptentwicklung und Softwareauswahl für Data & Analytics mit dem Fokus auf Datenmanagement & Data Governance. Er ist ein angesehener Redner und Autor und berät seit 2007 Unternehmen aller Größen und Branchen.

![[Translate to Deutsch:] silo photo](/media/Default/_processed_/6/5/csm_waldemar-brandt-7kSnMLGoR9w-unsplash_977a569c06.jpg)
