The GDPR Challenges Classic Data Management Approaches

Author: Stefan Reinhardt, Director Sales eccenca
The General Data Protection Regulation (GDPR) is not just a legal problem for companies. With its requirements, it directly interferes with operational processes - and thus raises technical and organizational challenges. Only by rethinking data management can these problems be solved in a sensible way.
The most important IT oracle has spoken. In its recently published "IT Trends 2019", the renowned New York-based analyst firm Gartner names the topic of "digital ethics and privacy" as a top 10 trend for the coming year, and the trend is increasing. The analysts warn that companies will be hit by protests in the future should they not proactively address people's concerns and offer solutions. This assumption is supported by various parties in the IT and data protection industry. For example, in its recent report "Future of Multi-Cloud (FOMC)", F5 Networks predicts that the GDPR will be quasi-globalized within the next five years through a worldwide standard for data protection. On a very practical level, this means that companies will have to deal with personal data in a completely different way.
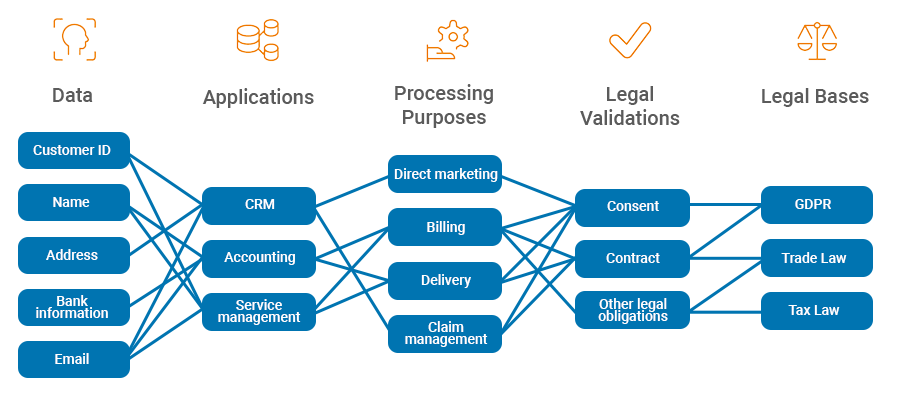
Subject Access Requests Are Just The Tip Of The Iceberg
The fall-out of this affects the day-to-day business, too. Those who want to comply with the GDPR requirements must decide how to do so in today's typical IT and data landscapes. After all, these usually consist of hundreds to thousands of applications and processes that come with their own data models, formats and (usually relational) databases. Unfortunately, with this data fragmentation and lack of clarity, even the often read and kind, but rather meaningless, advice to work with a structured database and to consider the extent and necessity of the data does not help (Security Insider, 02.08.18). Furthermore, the implementation of the GDPR rights of access, correction, deletion, restriction of processing and data portability is only the tip of the iceberg. Under the given IT landscapes, it gets even more interesting (and really costly) when it comes to day-to-day compliance in internal data processing.
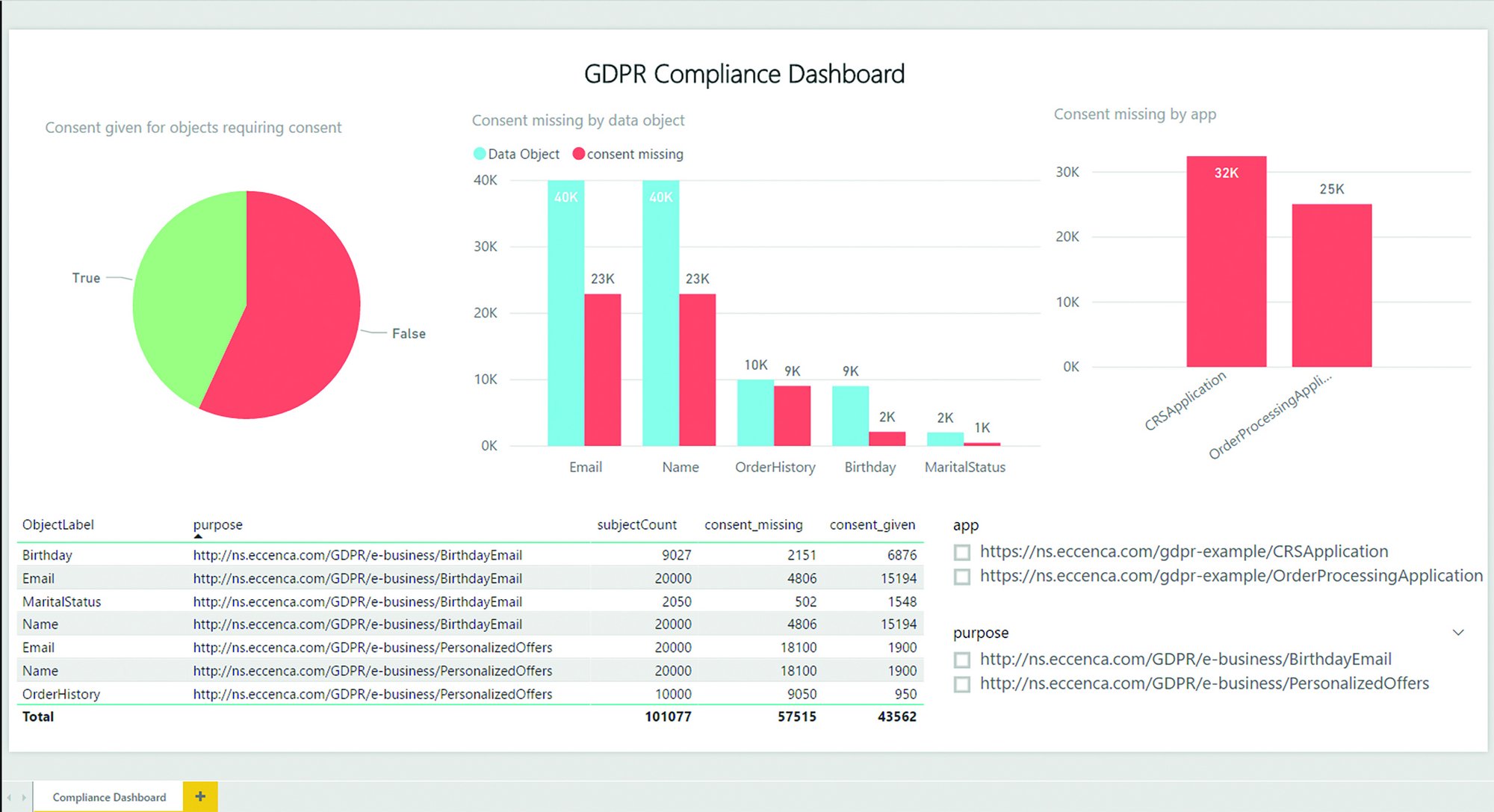
How do companies ensure, for example, that the consensus status of an individual for a particular processing purpose is known and synchronized across all applications? In addition, challenges arise for identity management. How can a consensus change of Jane Doe be efficiently implemented across all applications if she is listed as Mrs. Doe in one application and as Jane Doe in another? Or if the data fields in the applications are named differently? Should all the hundred to thousand application owners search for data on a person in their respective applications - including variations and possibly contradictory (e.g., outdated) data?
Rethink Data Management Without Hitting The Reset Button
The GDPR is therefore a multidimensional challenge: legally, in terms of customer relationships, marketing-wise, as well as organizationally and technically.
With this range of implications, data protection and the responsible handling of personal data both internally and externally are becoming a decisive unique selling point for companies. In doing so, they are faced with two supposedly conflicting challenges.
The solution:
- must integrate smoothly into the existing IT and data architecture without requiring extensive changes to the overall system.
- must not consist of isolated or makeshift solutions that postpone problems into the future, lead to high follow-up costs in the long term, and are inflexible.
The first challenge usually weighs heavier. So it' s no wonder that in the past, the second challenge was usually met with a blind eye. Or the data chaos was patched up with approaches such as complex master data management, data lakes and data warehousing. However, they remain inflexible and, above all, expensive.
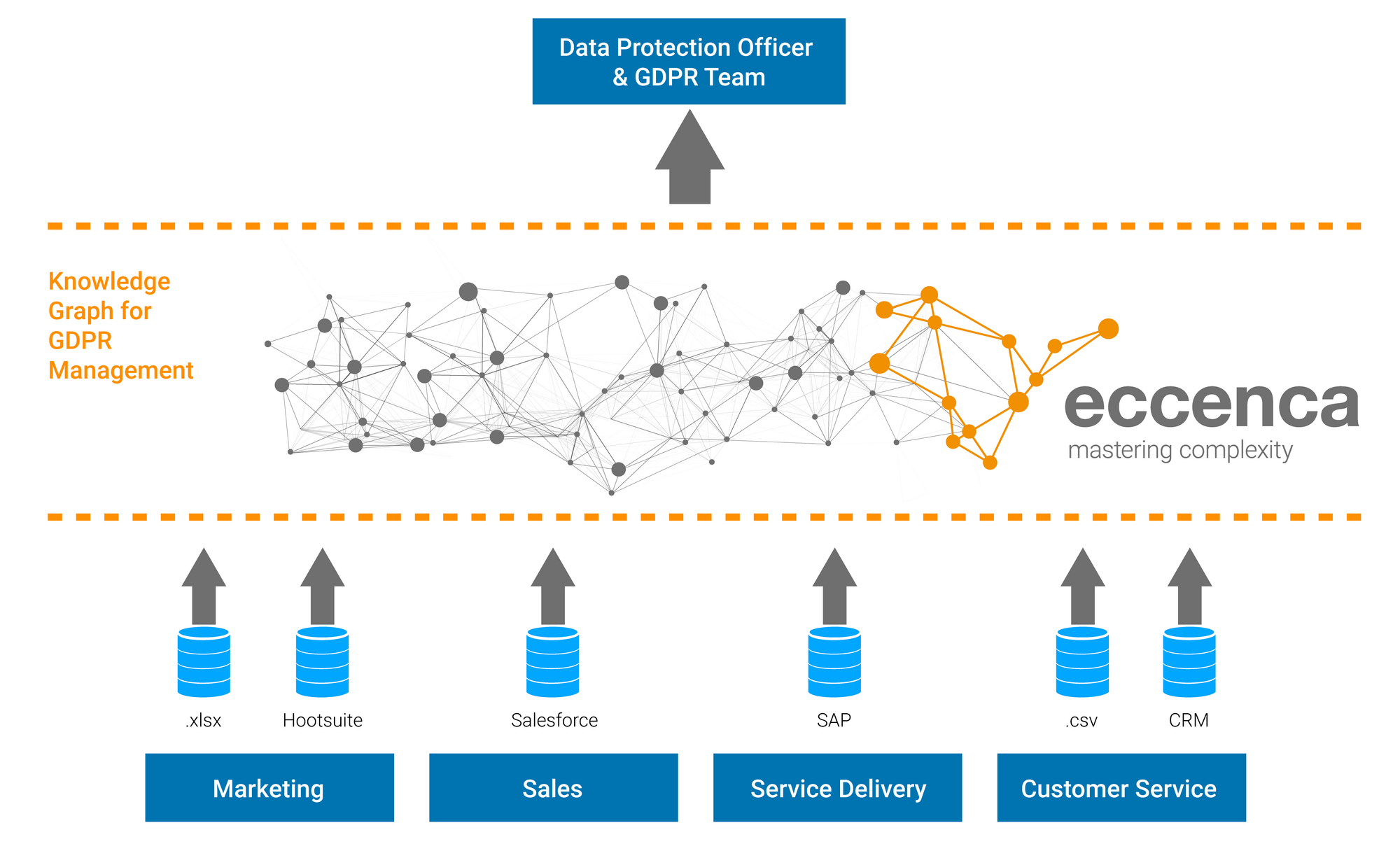
The Old IT House With A Semantic Roof
Every day, one particular ubiquous platform shows us how the chaos of heterogeneous data from a multitude of sources can be tamed, integrated and clearly presented. Since May 2012, the Google Knowledge Graph compiles the core information on a search query from the vastness of the World Wide Web in a clearly arranged info box. This also works at the enterprise level with personal (and other forms of) data - and does not require a complete change of the IT landscape.
The keywords here are semantics and metadata. Instead of tearing down the IT building, all that is needed is a new roof. The metadata of all data from the hundreds to thousands of applications is stored in a central semantic data catalog, enriched, linked and put into context with each other. Standardized data schemas (e.g., from schema.org) are used to keep the effort low and ensure the highest possible reusability. In the context of GDPR compliance, this results in an enterprise knowledge graph that provides information about:
- whether data on a person is stored or used in the company
- in which applications this data is held,
- which categories of data are stored in the individual applications,
- for which processing purposes consensus or other legal validation exists.
This gives companies complete, company-wide data transparency without having to change the existing IT infrastructure. The proprietary applications can still be used. The original data remains in their data models. Application owners do not have to manually do a wild card search for data on a person.
At the same time, the data is:
- freed from data silos,
- semantically linked with each other and
- directly linked to the requirements of the GDPR and legal validations.
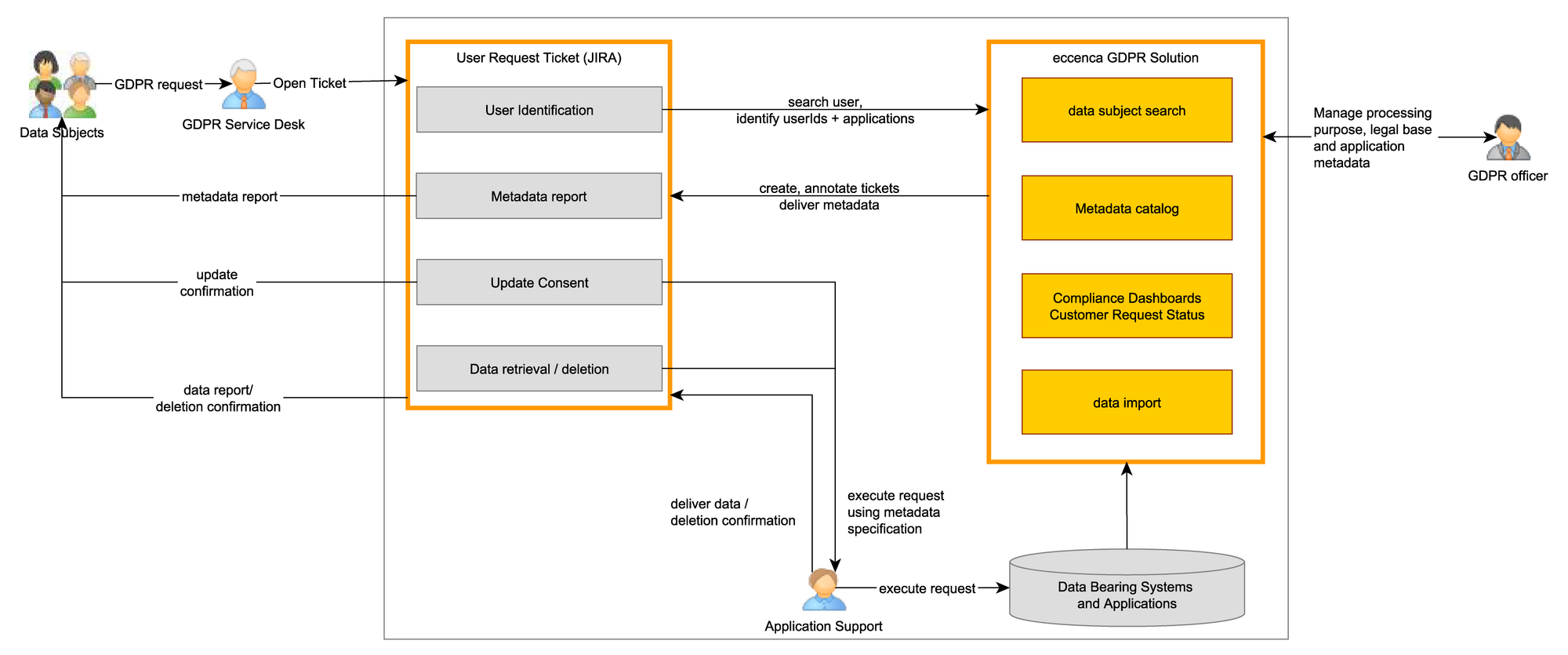
They can therefore be evaluated in context. Connected to a ticket system and an identity search engine, companies can organize and automate lean GDPR processes for information retrieval. This not only saves operating costs and valuable working time. The data protection officer also gains 100% control over company-wide compliance and can thus prove it consistently and automatically.
And since the semantic roof – the enterprise knowledge graph – can also be applied to all other data processes, companies are getting ready for the digital future as a side effect. With the foundation of structured, multidimensionally integrable and enriched data, the challenges of AI, digital supply chain, customer 360 and automation as well as new digital products and services become tangible for companies.
--
This article was first publish in German, Dec. 2018 in Big Data Insider.