Why FAIR Data Is Key To A Successful Digital Transformation

Author: Chris Brockmann, CEO eccenca
Everyone wants to be part of the success story of digital transformation, but very few are actually getting anywhere. Companies are failing because they are always talking about software and hardware solutions. But it all starts with the data. And that data is rarely managed in a way that meets the requirements of digital business models and efficient processes.
Digital transformation means one thing above all: acceleration. The winners of the digitalization will be the companies that can reduce their decision-making times. And who achieve a high level of automation through artificial intelligence to do so. In the financial sector and in large international e-commerce companies, this has already been evident for years. The winner is whoever can react fastest to the dynamics of the market or to a customer's order request. What do these pioneers of digital transformation do differently to most service and industrial companies? They manage to overcome the historically grown barrier between data, data silos, expert knowledge, business rules and the training requirements of artificial intelligence (AI). They achieve this through three capabilities.
First, they make implicit knowledge explicit. Data is only usable if we know what is behind that data. What kind of data is it? By whom and under what conditions was the data collected? What are the properties of the data? How is the data related to other data sets? The knowledge that is otherwise hidden in the heads of domain experts is thus digitally formalized. When this contextual knowledge is made explicitly accessible, humans and machines can both understand and use data in a flexible way across systems.
Second, they make the business rules behind the data explicit, which are necessary for the correct interpretation of the data. What decisions and conditions can be derived from the data? What limits do they set? This knowledge is thus extracted from the complicated, hidden software code and made explicit to its users. In turn, this enables a thorough quality assurance, traceable reasoning, and dynamic learning of AI.
Third, companies manage their data in a way that enables cross-system integration and processing. This allows companies to use and combine a variety of different data sources without drifting into data chaos.
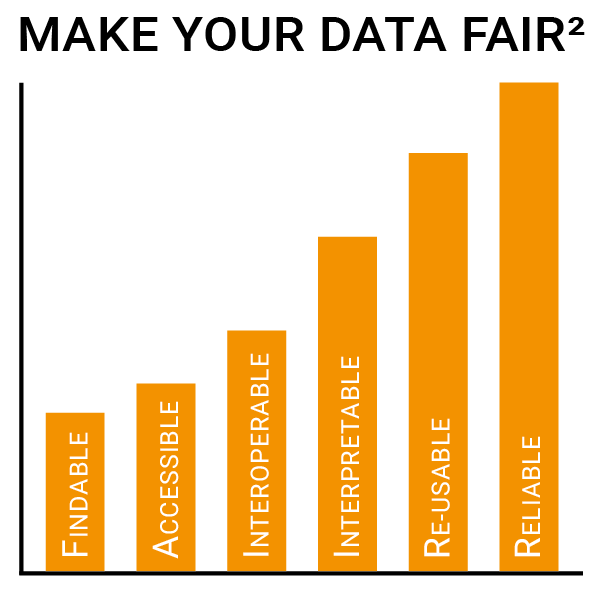
85 % Of All Data Is Garbage
How far away most companies are from these basics of digitalization is shown, among other things, by an evaluation of Aikux. The Berlin IT service provider Aikux analyzed the volume of files in 400 German companies. According to the study, each PC user has between 10,000 and 100,000 files in the internal file systems alone. Only 15 % of these are usable. The remaining 85 % is either data of unknown value or redundant, obsolete and unessential files.
Our experience with large enterprises shows that even structured data is rarely unambiguous, traceable, and usable across the board. For example, a good 50 % of all data in companies relates to one and the same thing. Employees are usually unaware of this redundancy because the contextual information is missing. The effect is well known to every company. For every data set, there is an expert who is the only one who can interpret and relate the data. And integration into a new system can only take place via complex transformation processes, which are frequently associated with information loss and blurring. This is also the reason why the results of Big Data and AI to date have been consistently sobering. The data basis for effectively training these applications is lacking.
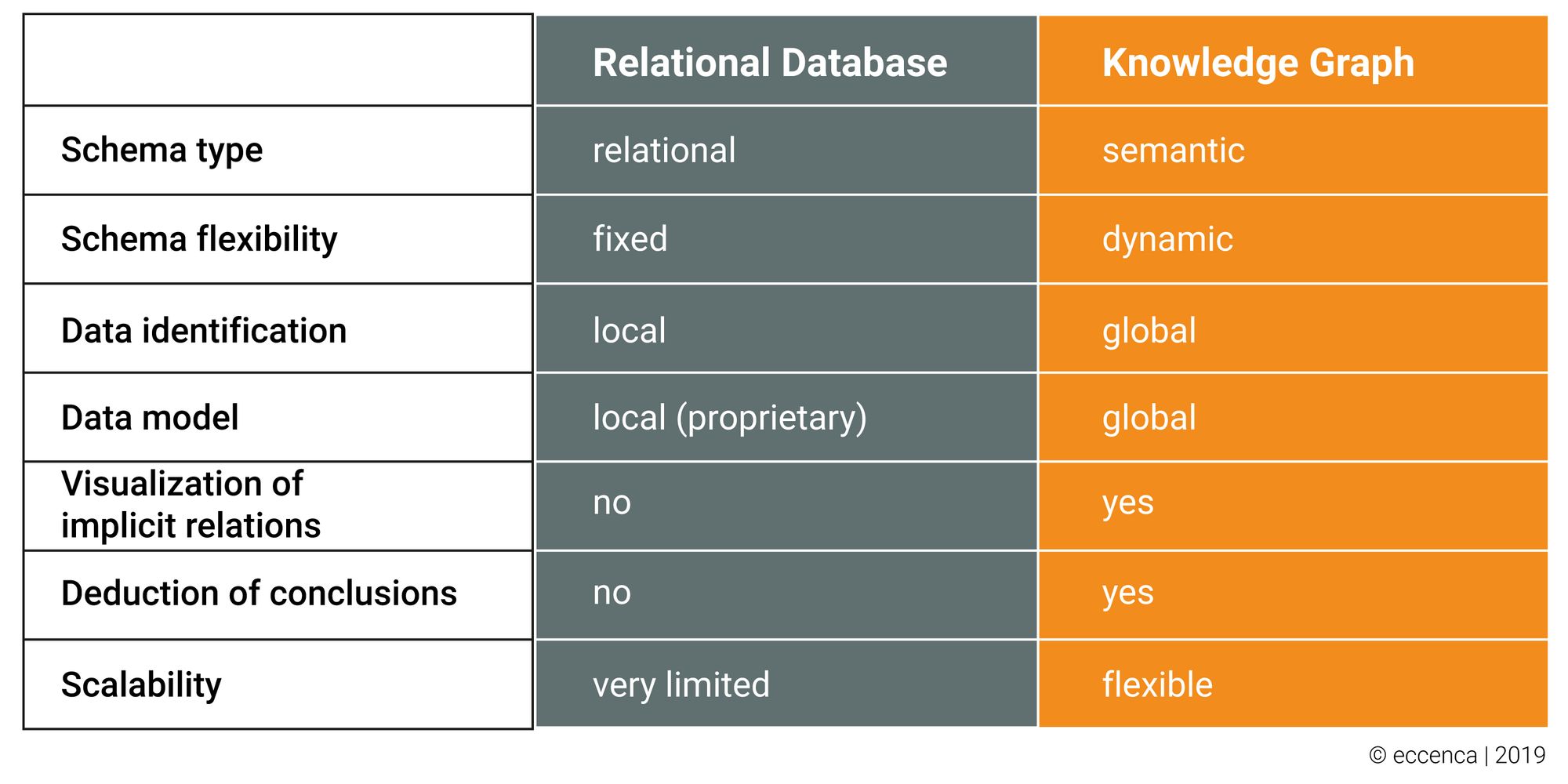
FAIR Data
In 2014, a consortium of scientists and organizations therefore developed the FAIR data concept. FAIR stands for Findability, Accessibility, Interoperability and Reusability. In essence, the concept addresses the challenges faced by every company. The (correct) data must be unambiguously identifiable and understandable, accessible and reproducible for the respective users. Since different users work with different programs and applications, the data must also be integrable beyond software boundaries. And finally, it should be possible to use data not just once, but as many times as possible.
To achieve this, the FAIR Data concept defines principles according to which data should be managed. Among other things, data should have a global HTTP identifier, regardless of the source system in which it is stored and processed. The cornerstone of the principles is semantic metadata, which enriches the raw data with contextual information. The metadata describes the actual data in terms of content, meaning and terminology, origin, processing, ownership, and relations with other data. This not only enables companies to find the data quickly. Metadata also enables cross-system and cross-domain interpretability, traceability, and logical linking. Metadata thus forms the decisive basis for using data to make the right decisions efficiently, purposefully and comprehensibly in the shortest possible time. The question for companies remains how they can establish FAIR Data in their own systems and, ideally, also with their business partner ecosystem.
Many Systems, One Option
The data silos that currently exist are not an option. Master data management and data migration projects have long promised to solve the problems. Within a narrowly defined framework, these options do lead to a certain degree of data consistency. However, they do not create FAIR Data. Most importantly, they fail to address the most pressing challenges: Data is dynamic and subject to constant change. Moreover, there is no unique truth to data, but rather - depending on the use case, domain, and nature - multiple truths. Ultimately, MDM and data migration approaches build just another data silo. They are therefore unsuitable for applications such as analytics, customer 360, digital supply network or automation.
Nevertheless, there is one sensible option. Companies can learn from the digital pioneers. The most data-intensive and successful companies in the world – namely Amazon, Apple, Microsoft, Facebook, Tencent and Alphabet – have long been using semantic knowledge graphs to manage the daily flood of data. This technology manages raw data entirely based on metadata. The raw data can still be stored and processed in the established source applications (from Excel to SAP to homegrown systems). A massive reconstruction of the existing systems is not necessary. The data is given a globally unique identifier and is enriched via metadata with the necessary contextual information outlined above in the Knowledge Graph. A Knowledge Graph can thus globally map the schema, semantics, and cross-linking of the data. This also allows AI applications to search, compare, and combine millions of data points in a very short time - deriving correlations, trends, and clear decisions. In short, knowledge graphs make data FAIR. Furthermore, knowledge of business rules can be documented in Knowledge Graphs in a comprehensible way. Algorithms are thus no longer dependent on the respective programmer, but are transparent for users, comprehensible in simple language and editable. The latter is indispensable, especially for the assessment of decisions and the further improvement of algorithms through machine learning.
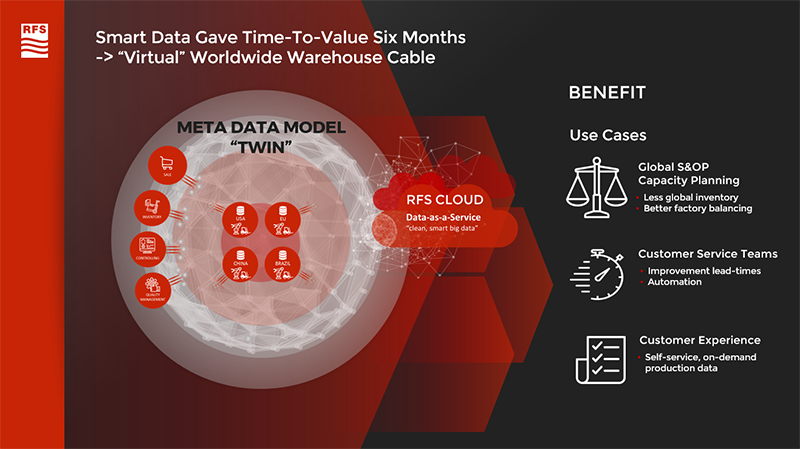
50 % Less Data Preparation
In 2018, the global corporation RFS (Radio Frequency Systems) proved the potential of Knowledge Graph technologies. The leading manufacturer of large components for telecommunications infrastructure built a global database for their product data within six months using the Knowledge Graph platform Corporate Memory. In the past, this data was managed locally at the 8 production sites on 5 continents. The reason were different IT systems, which managed the product data in their own formats and schema. The Knowledge Graph platform now enables RFS to search and compare product data and inventories globally. The local systems did not have to be adapted for this purpose. Not only did the group reduce its data preparation effort by 50 %, saving 22 man-months annually. The company was also able to reduce lead times with its customers and cut inventory by 12 % thanks to global product transparency. The project had a two-fold ROI after just six months. Read everything about the project right here.
This article was first published in German, Nov 2019, in the IT Management Magazine.